
To see the location of an AirTag second generation, you need to have an Apple device running the latest OS. For some reason, Find My online (website) does not show AirTags. Furthermore, older Apple devices won’t even help you. Sequoia on Mac is unable to see the AirTag second generation location – despite it still being a supported OS version. You need a device running Tahoe. AirTags second generation are surprisingly and unhelpfully incompatible.
Category: Technical Page 1 of 15
Well now, gather around children…
Once upon a time, the good developers wanted to save their users from losing changes if they left a form before submitting it. And as sometimes happens, Browsers looked kindly on the world, and provided the beforeUnload event, which could be hooked in Javascript so that changes could be automatically saved or a confirm dialog could be shown. The developers and users were overjoyed, and a golden age ensued.
But then enter the evil developers! These developers hooked the beforeUnload event to make the user’s life miserable. They coded event handlers so that people could never leave pages, and were stuck in a hell of eternal dialogs and never-ending pop-up windows.
The Browsers realised that beforeUnload had been a mistake, and something had to be done. The event was still needed by the good developers, but the evil developers had to be contained. So the event was changed to something “special”, and uncontrollable!
Thus code like this was born:
window.addEventListener('beforeunload', function(e) {
e.preventDefault();
e.returnValue = ''; // Triggers the browser's generic warning confirm, cannot be customised
}
});And it mainly worked. The evil developers were stopped, and the users were freed from the inescapable prisons of popups and alerts.
But the good developers wanted to write automated browser tests to ensure that the beforeUnload event worked, and that users would be saved from losing their changes forever. And this is where the tale becomes even sadder.
In Selenium / Firefox, no confirm dialog is shown from beforeUnload in tests, even though the confirm dialog shows during a usual interactive session.
In Cuprite / Chrome the story is more complicated. A message is shown on the console:
Modal window with text `` has been opened, but you didn't wrap your code into (`accept_prompt` | `dismiss_prompt` | `accept_confirm` | `dismiss_confirm` | `accept_alert`), accepting by defaultBut none of the ‘accept’ or ‘dismiss’ options work, or catch the dialog. They only work on normal JavaScript confirms and alerts. The only option is:
page.driver.browser.on(:dialog) do |dialog|
# I DO GET CALLED! BUT ASYNCHRONOUSLY.
endBut the dialog object cannot be accepted or dismissed, unlike all other dialog objects. It also has an empty message. Alas, our story ends a testing tragedy. The console warning message is always shown, and no significant test can be written, as the Cancel (dismiss) button cannot be pressed.
And so, to this day, the good developers must test this code manually, like it was the 1990s.
PS – do let me know if this tale is wrong and there is a better way…
PPS – Chrome, Edge and Firefox support beforeUnload in this way. But Safari on iOS ignores it. Safari on Mac largely supports beforeUnload, but after a cancel in the dialog to stay on the page, it doesn’t seem like the page can do a programmatic redirect from JS later (which other browsers allow).
Coding: Claude 3.7 for front-end work, especially with the help of Claude Projects to upload supporting files, and Extended Thinking turned on. Remember to always ask Claude to explain its plan before doing anything as it can get carried away. Claude 3.7 paid responds much faster than the free version.
Mobile App – Voice: I do like to sometimes ask questions using my voice and have a conversation with an AI who speaks aloud. The ChatGPT app does a great job of this, and has good support for image/video uploads as well (eg, identify this spider please). The other AIs interact in a far less “human” way – more like just text-to-speech. Again, this requires the paid subscription.
Deep research: Yes, it is Gemini 2.5 Pro Deep Research. Requests are limited and it is slow to give you an answer, but quite comprehensive. It writes you a long report but also provides a good summary of findings.
Tomorrow is a new day, expect change!
The fonts built into modern browsers are varied – it is hard to avoid loading your own fonts. Arial is the rare exception – it is well supported across all old and modern browsers. It looks a little different between Windows and Mac / iOS especially as a larger bold heading. On Android, it is substituted by Roboto. On Linux variants, Arial will likely fall back to the sans-serif system font.
Verdana is also well supported but looks a bit odd in this day and age.
You could instead go with the system font on each platform (eg, San Francisco for Mac/iOS, Segoe UI for Windows, Roboto for Android, etc). However, this means that every platform will look a little different, especially for larger and heavier font styles. Personally I like San Francisco and Roboto (and they look fairly similar). However, I find Segoe UI in large and heavy looks quite different and unsuitable for a “serious” website. If you could use Roboto on Windows reliability, this approach would be better.. but Roboto is only included with Edge but not Chrome on Windows.
So basically, if you want a “serious” looking sans-serif font that is similar across platforms, then it’s either Arial OR it’s time to load your own font and take the performance penalty in return for the look and consistency across platforms.
Google Fonts is a good place to get a font to self host. You can then convert the downloaded ttf with woff2compress (also available on brew) to make it a smaller download and host as a woff2. The woff2 format is now supported by all modern browsers.
A few months ago, when I was doing some detailed database backup and restore testing, I discovered there were, out of millions of records which had user-entered dates, a handful that had null dates in a database column. I scratched my head for a while and couldn’t work out how this had happened, as the field is validated in Rails for empty/null.
Just today, I got an exception report from a different part of the system which does a query based on the user entered date, and it revealed the source of this extremely rare problem! So.. drum roll..
Accidentally, a user had entered a date with the year 20223.
This is valid in Ruby/Rails but too big to be stored in the mysql Date column, so had ended up (silently) being stored as null!
Easily fixed by limiting the date range a bit!
Mysql 5.7 is reaching end of life in October, so it is becoming important to upgrade. I am using Percona Mysql and the upgrade process with Apt and the Percona repositories is simple. Mysql automatically upgrades files and tables to suit the new version too. There are config file changes required, and quite a lot of defaults changed in Mysql 8, but that is not the focus of this post.
Reading up on the performance differences from Mysql 5.7 to Mysql 8, the story is mixed. In my case, Mysql 8 is definitely slower out of the box for queries that are not well indexed. We are talking often about 50% slower on larger selects. With well indexed queries, the difference is negligible. I kept looking for some config setting that would bring back old Mysql 5.7 performance, but I found no way to make Mysql 8 perform as well out of the box. The solution I found was to add more indexes. These indexes had not been required in 5.7 for good performance. In Mysql 8, they proved vital.
Considering the difference in performance between versions, and additional indexes I had put in place, I wanted to test the performance before upgrading my production setup to Mysql 8. A good way to test performance would have been to mirror incoming requests between real production, and a cloned production server, and watch the comparative performance. This is arguable the best option, but requires quite a bit of infrastructure work and HTTPS offloaded from the production server to something that is mirroring the requests and ignoring responses from the clone. AWS supports traffic mirroring, but I decided it wasn’t the best option in my situation as it would have required significant infrastructure and production changes for my setup.
The alternative that worked in my case, was to record all database queries for a period of medium-high site load, and then replay these on clone servers, to test the relative performance between database server versions and index additions. Tools exist to do this, but they are a bit dated.
If you’re interested in using approach, first record all queries to file at a time of significant load, using the Slow Log on your production server (eg, for 10 minutes). Simultaneously, take a snapshot of the server that you can use for creating clone servers at this point in time.
To test relative performance on clones, I used Percona Playback. This is a very handy tool but old and unmaintained – still, it was the best option I found. To make Playback work, you need to run it under CentOS 7, which is easily achieved using Docker. I tried updating the code to run on modern Ubuntu but it was too big a job, libraries it depended on had changed too much.
To install, set up a data directory and grab and build my Dockerfile (I updated it a little from @lichnost’s version):
mkdir -p playback-docker/data
cd playback-docker
curl https://github.com/jcrisp/percona-query-playback/blob/master/Dockerfile > Dockerfile
docker build -t percona-playback .Transfer your query log (eg, MyServerName-slow.log) to the clone. I’d also recommend taking a snapshot at this point, and creating new clones for performance testing from this new snapshot, since it now has Percona Playback installed and the query log file available.
To replay the queries in full on a cloned database server:
docker run --mount type=bind,source=$PWD/data,target=/app/data --mount type=bind,source=/var/run/mysqld/mysqld.sock,target=/var/lib/mysql/mysql.sock percona-playback --mysql-max-retries 1 --mysql-host localhost --mysql-port 3306 --mysql-username <USERNAME> --mysql-password <PASSWORD> --mysql-schema <DATABASE_NAME> --query-log-file /app/data/MyServerName-slow.logNote that this is “destructive”. All updates/inserts/deletes will be applied, so the run is only fully valid once. Re-running it will lead to errors like duplicate ID inserts or deletes of records that don’t exist any more.
For a non-destructive performance test, you can filter out just the selects using another tool, pt-query-digest, which is happily still maintained and can be installed as part of the percona-toolkit package. To make a select only log file:
cat MyServerName-slow.log | pt-query-digest --filter '$event->{arg} =~ m/^select/i' --output slowlog > selects.log
For performance comparisons, I ran the non-destructive select-only version first to warm up the database before running the full destructive version as the real test.
This approach gave me confidence that, with additional indexes, Mysql 8 would be faster than Mysql 5.7 on a real production load for my app.
If you want to collect all queries running on your database for a period of time, for analysis or replay, the simplest way to do this is using the Slow Query Log.
To start collecting:
set global slow_query_log_file='/var/log/mysql/slow.log';
SET GLOBAL slow_query_log=1;
SET GLOBAL long_query_time=0;
SET GLOBAL log_slow_admin_statements=1;
SET GLOBAL log_queries_not_using_indexes=1;
SET GLOBAL slow_query_log_always_write_time=0;
set global slow_query_log_use_global_control="all";To stop collecting and revert setting changes:
SET GLOBAL slow_query_log=0;
SET GLOBAL long_query_time=10;
SET GLOBAL log_slow_admin_statements=0;
SET GLOBAL log_queries_not_using_indexes=0;
SET GLOBAL slow_query_log_always_write_time=10;The statements will be logged to:
/var/log/mysql/slow.logThe performance degradation from logging all queries was not significant in my case, with my site under medium-high load.
You may have to vary the slow_query_log_file location in the first line based on your configuration of secure_log_path.
I was writing a little function in Ruby and thought I’d ask ChatGPT to have a go at it.
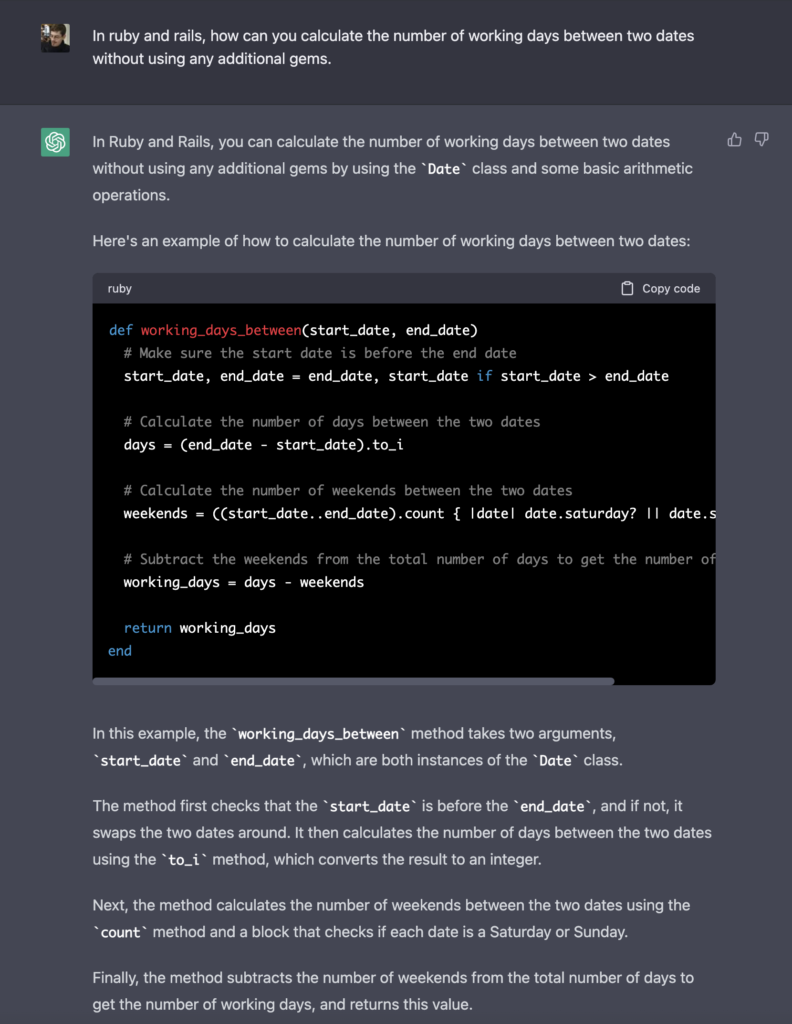
It is easy to read, explicit, and fairly idiomatic Ruby (though not concise). Not the most performant implementation but nothing terrible. It also mainly works but does have a bug in some cases.
Here is the code:
def working_days_between(start_date, end_date)
# Make sure the start date is before the end date
start_date, end_date = end_date, start_date if start_date > end_date
# Calculate the number of days between the two dates
days = (end_date - start_date).to_i
# Calculate the number of weekends between the two dates
weekends = ((start_date..end_date).count { |date| date.saturday? || date.sunday? })
# Subtract the weekends from the total number of days to get the number of working days
working_days = days - weekends
return working_days
end
If you have the start/end date on a weekend, then you get a negative answer. Eg,
working_days_between(Date.parse("Sat, 04 Mar 2023"), Date.parse("Sun, 05 March 2023"))
=> -1It is because the weekend number of days calculation is including both the start date and the end date. Ie, working_days = 1 – 2 = -1
A human could easily have made the same mistake, mind you.
A better / simpler implementation is:
(from_date...to_date).count { |date| date.on_weekday? }Note the 3 dots (…) for the date range, which does not include the end date.
Later, I tried asking ChatGPT to regenerate the answer multiple times. It gave me quite a different version every time – some versions with bugs, some with no functions, some with support for public holidays, etc.
Tune in to the next Sydney ALT.NET meetup on Tuesday (30 Dec)! I’ll be giving a talk from around 6pm.
Accept credit cards: Gateways, architectures, code, and… money!
Have you been thinking to accept credit card payments for your new clever MVP, startup, or maybe even in your day job? Well, you’re in luck! James will give you a primer on how to do it simply and securely, based on his recent journey to the Gateway jungle.
Please RSVP on meetup and join the Twitch stream for some fun!
So maybe you have a model that is not backed by a database table? ActiveModel is meant to cover this scenario and give you the usual ActiveRecord goodness and validation.
But the story gets much harder if you want to have nested objects. In a normal ActiveRecord::Base backed model, you can simply say:
accepts_nested_attributes_for :order_lines
and Rails will manage form submitted nested parameters for you.
Life is not so simple, or documented with nested objects on ActiveModel. accepts_nested_attributes_for is not available. But some of the underpinnings are.
So enough talk, how do you make it work? I’ll show you with an Order / OrderLines example.
Note the very special name: order_lines_attributes=. This hooks into the Rails handling of nested form parameters. Also the valid? method propagates the child errors up to the parent object, so that they show up at the top of the form.
Now how do you do the nested form? It’s similar to normal database backed nested records.
Hope this helps, it is not documented anywhere I could find, and worked out mainly though reading the Rails source.